Engineering
Mar 24, 2026
Why Kubernetes Serving Breaks Down for Real-Time AI

Eli Roussos
Founding Engineer
Kubernetes Is a Strong Foundation for AI Workloads, but Default Serving Patterns Often Fall Short
Most teams running AI workloads today end up using Kubernetes, which makes sense at first glance. Kubernetes gives you scheduling, isolation, service discovery, rollouts, and a huge operational ecosystem. It is a strong substrate for deploying models and managing infrastructure.
But serving a variety of AI workloads reliably at scale is a different problem.
Many of the serving patterns people inherit around Kubernetes were designed for traditional web workloads: pods that handle many concurrent requests, readiness that is mostly binary, and routing mistakes that are often absorbed by retries and spare capacity. Many inference workloads do not behave like that.
For a large share of latency-sensitive GPU workloads, effective concurrency is extremely low. In many cases, a single instance is serving one request at a time. Model load times are long and variable. Pods can be alive but not truly ready to serve. Response times can vary from a few hundred milliseconds to tens of seconds or even hours in some cases.
Under those conditions, routing becomes significantly more sensitive. A wrong routing decision is not just a small inefficiency. It can burn the only available slot on an instance and surface immediately as latency or a 502 to the user.
Kubernetes is a good foundation, but its default serving patterns started to fall short under the behavior of real inference workloads. At Cerebrium, we had to adapt the architecture around user workloads. Below is our journey in doing so.
The first architecture: queue-based dispatch
Our first system 3 years ago followed a pattern that will be familiar to many teams.
When a user deployed a function to Cerebrium, it ran on Kubernetes inside a custom Python runtime. Requests came in through our API layer, were serialized as Celery tasks, pushed into a broker, and then pulled by workers running on GPU nodes. For scaling, we used KEDA to watch queue depth and adjust replica counts accordingly.
Diagram 1: Initial queue-based architecture
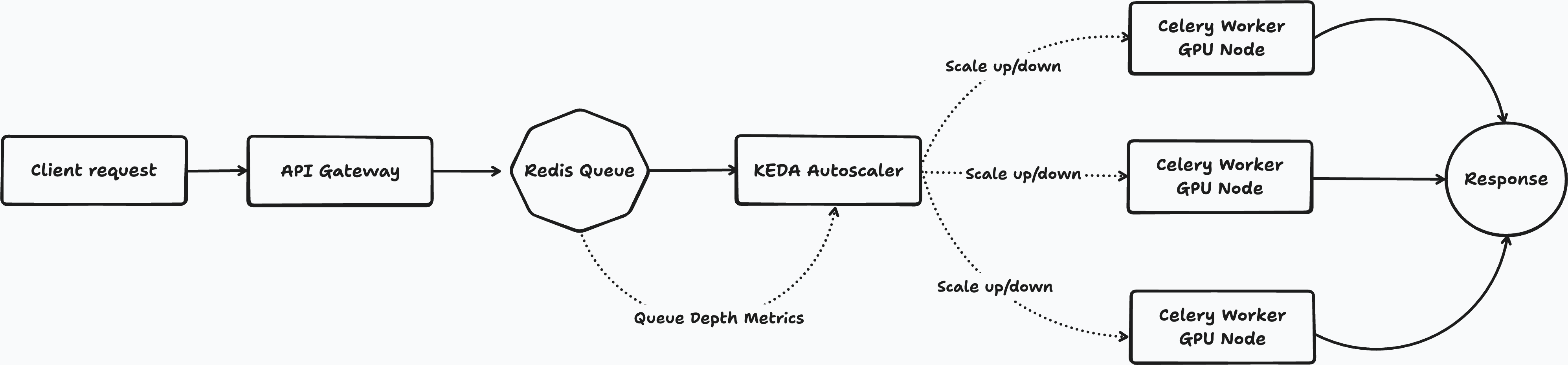
This was a reasonable place to start. Queue-based systems are common, battle-tested, and work well for asynchronous processing. They are a natural fit for background jobs, batch pipelines, and workflows where throughput matters more than immediate response time.
But they broke down for synchronous, low latency inferencing.
The first issue was pull-based dispatch. Workers poll for work. That means there is always some delay between a request arriving and a ready worker actually picking it up. For an async job system that is fine. For an inference API, it adds latency in exactly the wrong place.
The second issue was slow reaction to demand. KEDA scaled on queue depth, which meant the system reacted only after requests had already begun piling up. By the time new pods were scheduled, images pulled, and models loaded into memory, the backlog was often already too large. Queue depth told us demand was rising, but not whether real serving capacity was available quickly enough to keep the user experience intact.
The third issue was lack of request-time readiness awareness. A queue knows that work exists. It does not know whether the workers that will eventually consume that work are actually ready to serve inference right now. For AI workloads, that distinction matters a lot.
The lesson was simple: a queue is a useful abstraction for async processing, but often the wrong abstraction for low-latency synchronous inference.
Why AI inference changes the serving problem
The deeper issue was not Celery or KEDA specifically. It was that user workloads violated some of the default assumptions behind common serving patterns.
1. Low effective concurrency makes every route matter
A typical web server can handle many concurrent requests. If one request lands on a pod that is momentarily unhealthy, the blast radius is often limited. Retries and excess capacity can then compound delays, while undermining true performance benchmarks.
Inference is often different. For many GPU-backed workloads, the practical model is much closer to one model per instance and one request at a time.
That means every routing decision becomes load-bearing.
If traffic is routed to the wrong place, you have not just slowed one request among many. You have used the only slot that instance had available. The user feels it immediately.
2. Kubernetes readiness is often too coarse
For web workloads, readiness is usually good enough if the server is up and dependencies are reachable.
For inference, a pod can be technically alive and still not truly ready to serve.
The model may still be loading. GPU memory may still be initializing. User code may intentionally move in and out of readiness while cleaning up state. A Python event loop may be blocked even though the pod still appears healthy from Kubernetes’ point of view.
So the question is not just, “Is this pod ready?”
It is, “Can this target actually serve this request right now?”
That distinction becomes critical when each instance has very little concurrency to spare.
3. Routing becomes part of the product experience
In traditional web systems, routing is often treated as a generic layer. A load balancer picks a target and traffic moves on.
For AI inference workloads, routing is much closer to the product itself.
If the router is working off stale readiness information, users see failures. If the router cannot react quickly when a target becomes unavailable, users see failures. If the router does not distinguish between a pod that exists and a pod that is truly servable, users see failures.
That changes the architecture. The routing layer cannot just know what pods exist. It needs a significantly more accurate picture of real serving availability.
Diagram 2: Why inference routing is different
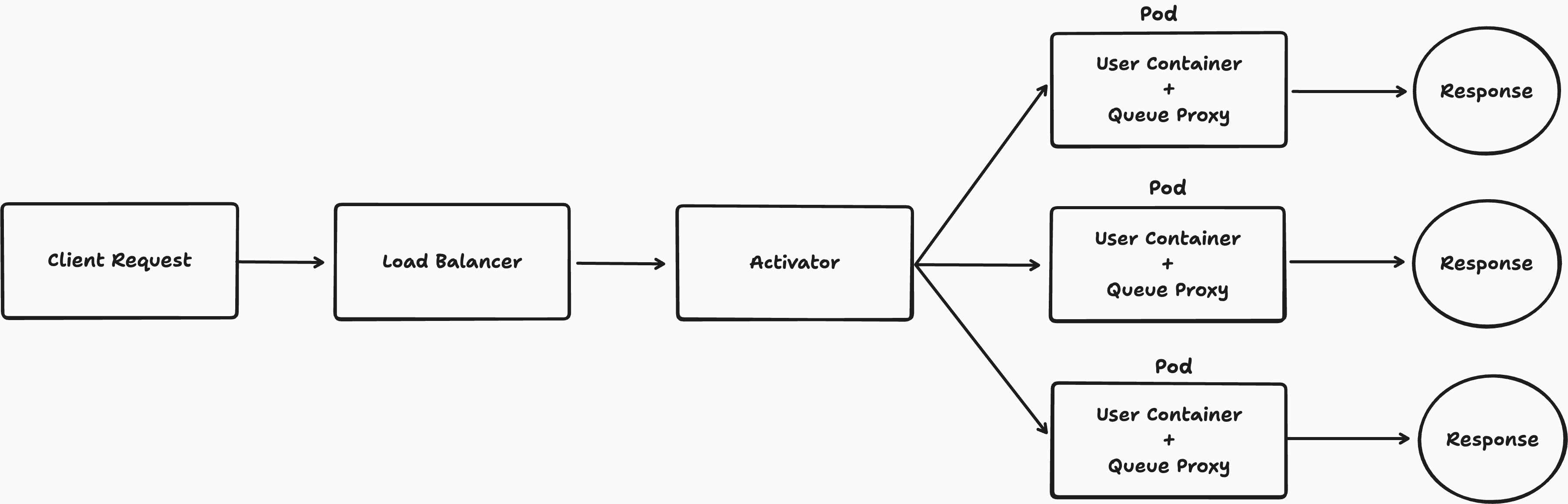
A request arrives and the router sees three pods:
Pod A: running, but still loading the model
Pod B: marked ready in Kubernetes, but not accepting traffic cleanly
Pod C: actually ready to serve
For many inference systems, only Pod C is truly eligible, even if Kubernetes makes the situation look less clear.
What we changed at Cerebrium
Moving away from queue-based dispatch got us much closer to the serving model that low-latency inference requires. Requests could be routed directly to available capacity, scaling could react to live demand instead of queue depth, and concurrency limits could be enforced before traffic ever reached user code.
But under real AI workloads, especially low-concurrency GPU inference, the default serving model was still too coarse.
The routing layer still relied on assumptions that work far better for traditional web traffic than for inference. Readiness information could be stale. Targets could appear eligible while they were in the middle of a transition. And when each instance only had one slot, even rare routing mistakes became visible to users.
We addressed this by adapting the serving layer around the actual behavior of user workloads. The main changes fell into three buckets:
Moving routing decisions closer to real application readiness
Turning transient target failures into recovery events instead of user-facing errors
Making routing state consistent even as the system scaled out
1. Moving routing decisions closer to real readiness
One of the first things we learned was that Kubernetes readiness was often too indirect or degraded/lagged at scale for inference serving.
If the router relies only on Kubernetes control-plane state, it is always working with information that has passed through multiple layers: the application updates readiness, the kubelet observes that state, the API server updates endpoints, and informers eventually reflect the change. At scale, this lag could be longer than 10 seconds.
Pods can move in and out of a truly serveable states much more dynamically than traditional services. A model may still be loading. A container may be releasing GPU memory between requests. User code may temporarily block the HTTP server even though Kubernetes still considers the pod ready. In all of those cases, the router can briefly believe a target is eligible when it is not actually able to accept traffic cleanly.
That mismatch was enough to create 502 status codes - unhealthy upstream.
So one of the first changes we made at Cerebrium was to move the source of routing truth closer to the application itself. We used readiness updates from the queue-proxy (QP), which sits directly next to the user container and probes it continuously, to feed serving state into the router in near real time. The Kubernetes informer still remained in the system, but as a fallback and for initial discovery rather than the primary source of truth.
That sounds like a small distinction, but it materially improved how quickly the system could react to pod transitions. At scale, readiness propagation dropped from 10+ seconds to under 200 ms, even while supporting roughly 5× more workloads. Under low-concurrency compute loads, that difference is large enough to meaningfully reduce routes to targets that are technically alive but not yet ready to serve.
2. Adding a reactive recovery path for bad targets
Even with better readiness information, some data race conditions remained.
A target could be marked ready and still fail at connection time because it was mid-transition. A user process could block unexpectedly. A target could be reachable one moment and not the next. For highly concurrent web workloads, these events are often diluted by retries and spare capacity. For single-request inference workloads, they are much more visible.
This begs the question - how do we distinguish between two very different cases:
the application itself failed while handling a request
the router chose a target that should not have been eligible in that moment
Those are not the same operational problem, and they should not be handled the same way.
So we introduced a quarantine path for targets that failed before request handling had really begun. When the router selected a target and the connection failed at the transport layer, that target was immediately removed from the eligible pool and placed into a temporary recovery flow. Health checks ran asynchronously, and only once the target proved it was servable again did it re-enter the routing pool.
This gave us two benefits.
It stopped the router from repeatedly sending traffic to the same unstable target.
It converted many transient failures from repeated user-facing errors into short-lived control-plane recovery events.
This was especially important because some of the failure modes were not bugs in user code. They were timing mismatches between observed readiness and actual servability. The system needed to absorb those mismatches rather than leaking them directly to end users.
3. Replacing binary health with explicit pod states
Once we moved closer to real readiness and added quarantine, we had effectively outgrown a simple healthy/unhealthy view of a pod.
For inference workloads, that binary model was too lossy. There was a meaningful difference between:
Ready to receive traffic
Not yet ready
Temporarily bad and under recovery
Draining and leaving the pool (we run many pre-emptible workloads)
Treating those all as some variation of “not healthy” made it hard to reason about the routing layer and easy to introduce subtle state bugs.
So we moved to a richer pod state model.
At a high level, a target could now be in one of a small number of explicit routing states, for example:
Ready: eligible for traffic
Not ready: not yet eligible
Quarantined: temporarily excluded while recovery is in progress
Draining: intentionally leaving service
That let us make routing and recovery logic much more precise. A quarantined target was not the same as a cold-starting one. A draining target was not the same as a broken one. Those distinctions mattered both for correctness and for observability.
It also made rollout safer. Once target behavior is represented as explicit state transitions, you can gate features, validate transitions, and debug the system much more systematically.
4. Serializing routing state updates
As soon as routing state started getting richer, another systems problem appeared: concurrent mutation.
Serving-state updates were arriving from multiple places at once. Readiness changes, recovery decisions, pod lifecycle events, and control-plane updates all wanted to touch the same target state. Without strict coordination, it became possible for one part of the system to mark a target recoverable while another part was simultaneously moving it into a different state.
That kind of race is survivable in many distributed systems. In a low-latency routing path, it quickly becomes painful.
So we centralized state mutation behind a single serialized update path. Rather than allowing many parts of the system to write routing state directly, updates flowed through a dedicated state manager that processed events in order. The routing hot path could still read fast, but writes became coordinated and consistent.
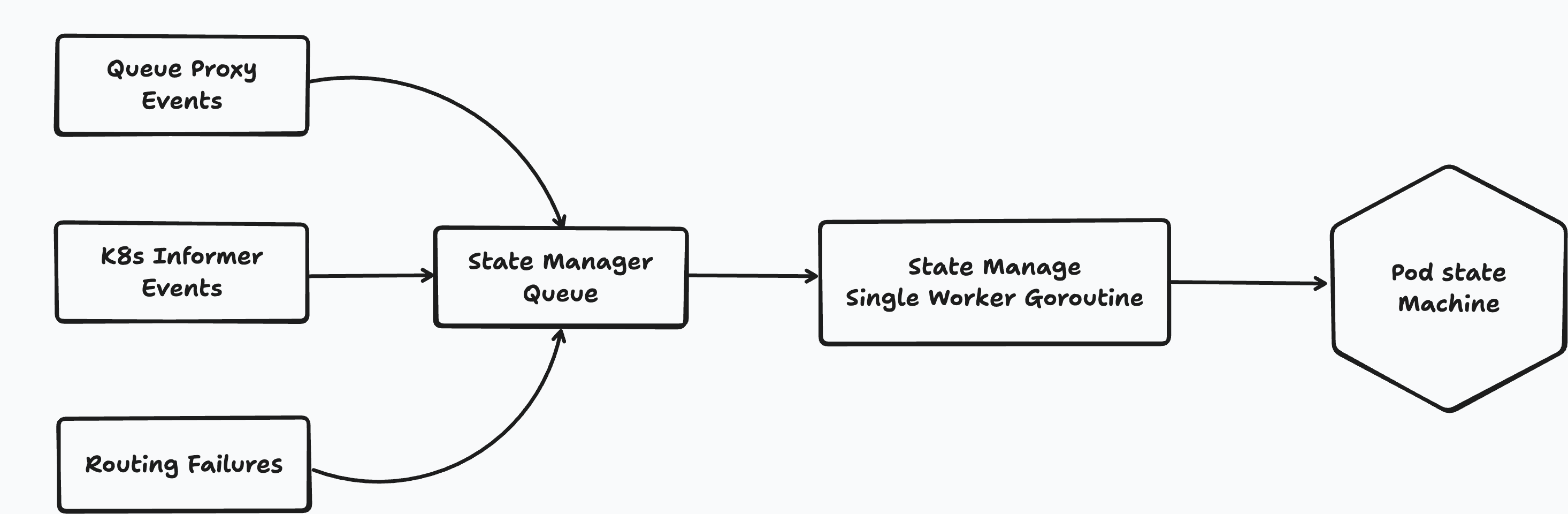
This made the system behave more like an actor model: many inputs, one authoritative mutation path.
That design gave us stronger invariants around state transitions and reduced an entire class of subtle concurrency bugs that would otherwise have shown up as intermittent routing failures.
6. Distributing routing state without losing global awareness
For a while, we kept the routing decision space centralized on purpose.
That gave us a global view of all available targets, which mattered because sharding the routing pool works badly for inference workloads with very uneven request durations. If one router only sees a subset of pods, it can appear saturated even when free capacity exists elsewhere. For low-concurrency inference, that kind of fragmented view leads to bad routing decisions.
But centralization created its own limit. As traffic grew, a single activator became the bottleneck.
The good news was that we had already built the routing layer around a clean state boundary. All state mutations flowed through the state manager, while the routing path only read consistent snapshots. That meant we did not need to redesign the routing logic itself. We needed to move its backing state out of process and into something multiple router instances could share.
That external state layer had two requirements. Reads on the routing hot path needed to stay extremely fast, and the store itself needed to be highly available. An in-memory distributed store was the natural fit, so we moved routing state into Valkey.
The pod state machine, IP ownership registry, and recovery state all moved out of local memory and into shared storage. Per-pod state was stored explicitly, per-revision membership was tracked separately, and state changes were published so other router instances could update their local view quickly.
From there, router instances split into two roles. One instance handled authoritative state mutation: processing QP readiness updates, informer events, and quarantine decisions, then writing those changes into Valkey and publishing them out. The others bootstrapped from shared state and consumed the update stream continuously. All of them still served traffic. The difference was not who could route requests, but who was allowed to mutate routing state.
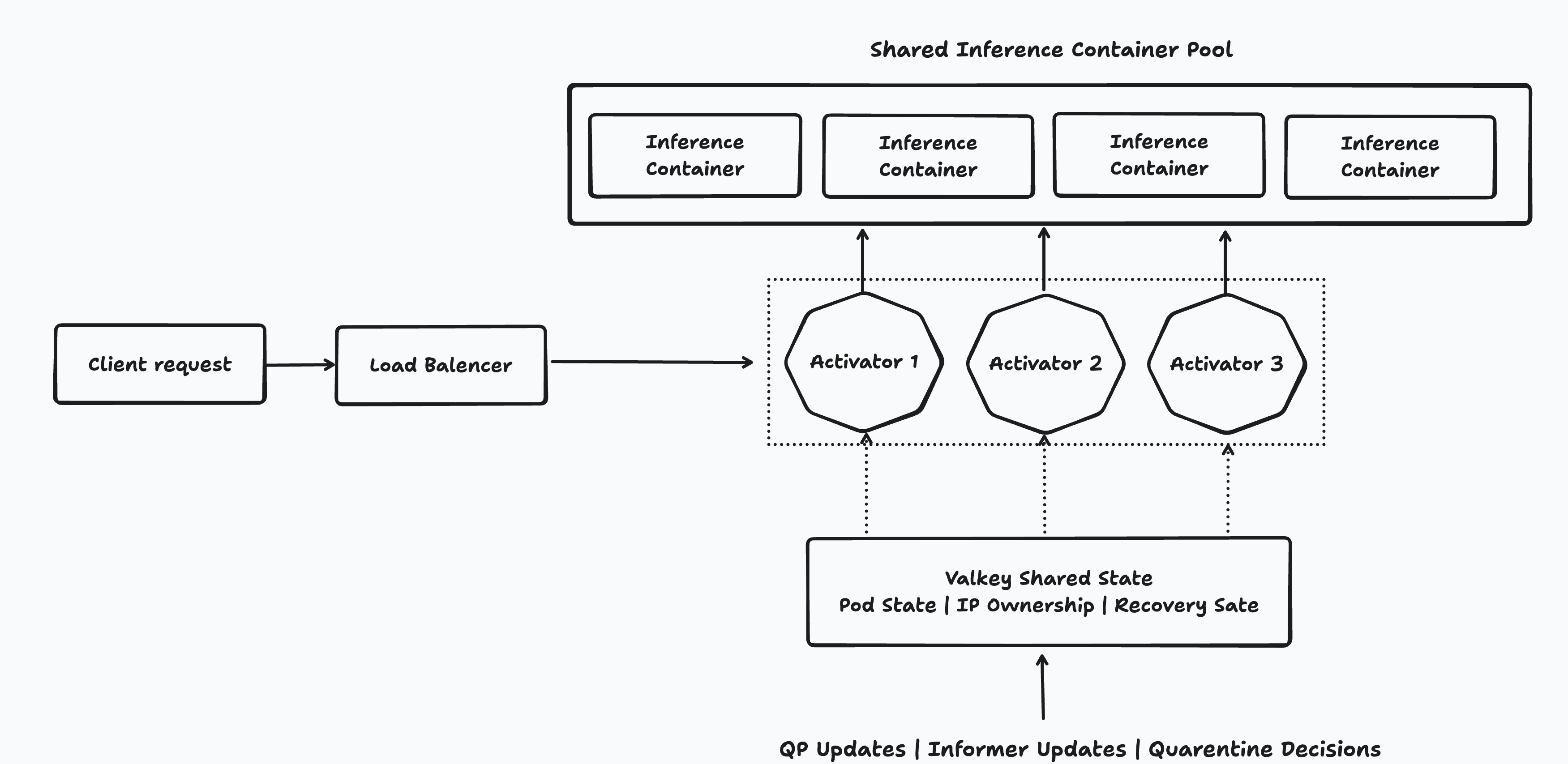
That architecture let us scale the routing layer horizontally without giving up the global view that made routing accurate in the first place. Once routing state lived in a shared backend, the activator became significantly closer to stateless compute sitting on top of a shared control plane.
What changed in practice
The architecture evolved in stages: from queue-based dispatch, to direct request routing, to richer pod state, to a shared routing control plane built for high churn and low-concurrency workloads.
Each step was forced by workload behavior, not by a desire to build custom infrastructure for its own sake.
In practice, those changes fundamentally altered how the platform behaved under production traffic. Requests became far less likely to be routed to targets that were technically alive but not actually servable. Transient target failures stopped repeating as user-visible errors. Readiness transitions became faster and more accurate. Routing state stayed coherent even as pods were starting, stopping, draining, and recovering continuously.
Today, that architecture lets us support tens of thousands of pods in each region we operate, while keeping routing overhead to a p90 of roughly 25 ms. That is the real outcome of all of these changes: not complexity for its own sake, but a serving stack that can handle the churn, unevenness, and sensitivity of real-time AI workloads at scale.

